
Today’s vehicles rely heavily on complex electrical systems to provide advanced features. Although these systems provide many convenience and safety enhancements, they introduce new failure modes which must be addressed by appropriate diagnostics and diagnostic architecture.
The use of electronic parking brakes (EPB) over manual lever-actuated parking brakes imposes new requirements for advanced diagnostics to ensure proper brake operation and the functional safety of the vehicle. The development of an EPB controller by Dana provides insight into several often-underappreciated aspects of diagnostic architectures.
Diagnostics Overview:
The role of diagnostics in any control system is to detect anomalous or undesired operation of a component or components in that system. Diagnostics have an immediate impact on both system availability (ability of a user to perform some task) and functional safety (the absence of unreasonable risk due to hazards caused by malfunction behavior[i]). A diagnostic that detects a fault when one is not present (a false positive) can cause a driver to be unable to perform some task. This may be a nuisance, such as not being able to select a desired channel on the radio, or something more severe rendering the vehicle inoperable. A diagnostic that fails to detect a fault may also result in a hazardous situation. For EPB systems, the most severe fault is a sudden application of braking force when driving at high speed. Failure to detect such a fault has a high probability of resulting in a high-severity, low-controllability situation.
A park brake is often the only retention mechanism for electric powertrains due to the lack of driveline resistance to freewheeling. As such, the combination of the need for availability and functional safety requires balance in the system design and approach to diagnostics. Immobilizing a vehicle is a safe condition in response to faults, but has a dramatic adverse impact on vehicle availability.
Example topology:
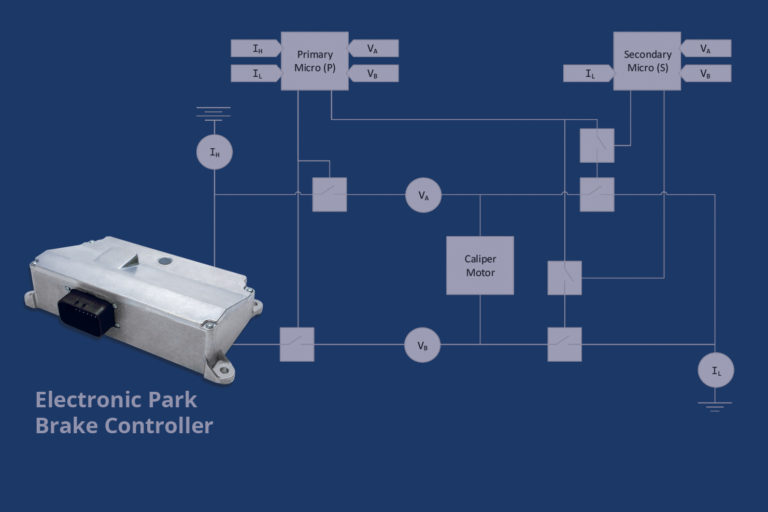
For high availability and high functional safety, EPB systems typically employ redundant processing components, which work in concert, providing braking when needed and preventing unintended braking. Figure 1 shows the example control topology used discussed in this paper.
This topology provides detection of and protection against:
- Unintended actuation
The secondary microcontroller can open the low-side path independently of the micro, preventing inadvertent control from the primary. Current-monitoring on both legs can detect shorts to supply, or ground outside the controller.
- Actuation in wrong direction
Both microcontrollers measure voltage on both terminals of the caliper, providing independent, redundant measurement of direction.
This topology provides detection against
- Failure to actuate
Redundant voltage and current measurements can detect failure to actuate due to incorrect command, and due to some failures of gates and external components. Load-off shorts and open can be detected by measuring terminal voltages with zero, or only one high- or low-side, gate active.
Approach to diagnostics
The fault management strategy is as important as the technical details of fault detection and mitigation. A fault management strategy consists of several main concepts:
- The fault life cycle. When to set faults, when to clear faults, and how to report faults.
- Awareness of diagnostic capabilities of hardware components and the relationship to safety analyses.
- Coordination of fault detection, and response among distributed processing components.
Life cycle
The diagnostic life cycle in this paper is defined as the cycle of detecting a fault condition, confirming the fault, then acknowledging a return to the absence of the fault condition.
While the criteria for determining the presence of a fault condition is normally well understood (e.g. detecting current when none is expected, which indicates unintended actuation), the conditions for returning to a fault-absent state are less clear.
The available choices for returning to fault-free behavior fall into one of several broad categories:
- Simple debounce
- Drive-cycle debounce
- Condition-based debounce
- Manual/service recovery
The type-of-fault recovery mechanism must be informed by the functional safety analyses for the system.
Some examples from an EPB system are tabulated below.
| Fault | Fault Recovery Method | Rationale |
| Wrong command to motor | Manual/service recovery | A wrong command to the motors indicates a fault within the microcontrollers or drive circuitry which can only be rectified by controller replacement. |
| Overtemperature and/or transient Current Trips | Simple or condition-based (time) debounce | Temperature and current faults can be due to transient environmental conditions, meaning a retry or delay-and-retry scheme is appropriate. |
| Open / Short circuit detection | Manual/service recovery | Open and short circuits indicate either a failure of drive circuitry or a failure in external components, such as harnesses, which warrant inspection and/or repair. |
Consideration of hardware capabilities
Hardware capabilities of a control module are intrinsic to the diagnostics available on a module. The specific use cases for which a controller is designed, drive the part selection, which has a specific impact on the diagnostics.
EPB controller output drivers are a hardware component of particular interest. Modern output driver chips often have built-in capabilities for detecting, and automatically protecting against, temperature and current excursions. Some chips also include built-in facilities for open- and short-circuit detection with the load commanded on or off. While this can be convenient, it is important to ensure the method of reporting those internal driver states, to the application, is well understood. Some chips, for example, may report a single status bit to the application rather than individual status bits.
EXAMPLE: An H-bridge chip, providing a single bit, indicates a fault but does not disambiguate between overcurrent, over-temperature, or open-/short-circuit. The application software must use multiple sources of information to determine the fault, and then associate an appropriate fault action. In Figure 1 – Example EPB Topology, the independent current measurements outside of the driver chips allowed disambiguation between excessive current, and driver overtempt faults.
Coordination of fault detection and response
The most challenging aspect of managing faults is related to safety mechanisms on the EPB topology. In a topology, as in Figure 1, there are two independent computation units, each capable of independently disabling the outputs. Care must be taken to handle how an intervention by one computation unit is interpreted by the other computation unit.
In a naïve implementation, the primary microcontroller is likely to detect an open-circuit fault if the secondary microcontroller disables the caliper motor. To avoid nuisance faults, the secondary micro must be able to communicate to the primary that it is actively intervening. This may require high-frequency communication, since the fault handling time intervals are short for EPB.
Fault reporting
Once the application has detected a fault, the final aspect of fault management is the reporting concept. There are two scopes of fault reporting: indications to the vehicle operator, and fault reporting for diagnostics and service.
A driver needs to know if a feature is available or not, ideally before needing that feature. A diagnostic that detects potential latent failures should be indicated to the driver as soon as the failure is identified. Generally, drivers only need to know that something will likely not work as expected. The cause is not relevant information to the driver. Additional diagnostic indication should direct the vehicle operator to a course of action, rather than only indicating a fault.
For service tools, much more detailed information is necessary, often including best estimate of root cause to direct repair activities. An internal EPB controller fault should be distinguished from a caliper fault, for example, with a specific fault identifier.
Concluding remarks
A technical consideration alone, of how to detect and address faults in modern vehicle systems, is not sufficient. It requires a holistic approach. The fault detection and management architecture must satisfy the requirements for functional safety, while maintaining reasonable vehicle availability. The fault indication strategy must be able to provide guidance to the vehicle operator, without being distracting or providing non-actionable information.
[i] ISO 26262-1:2018 Clause 3.67
 Accessibility
Accessibility